The Structure of Memory Is the Structure of Truth
by Jacob Koenig
6/23/26

What I learned when my AI turned two truths into a big fat lie
My AI lied to me this week, even though every fact it used was true. It pulled from my curated memory system, but it pulled across contexts that aren’t meant to mix, and then strung together an assertion to make it all “make sense”.
My first instinct was that my memory files had just grown too big and bloated…but AI doesn’t have trouble with scale. The notes were correct and sat right where they belonged, with timestamps to boot. But I came to realize that my system that stores and retrieves memory could also serve to confuse instead of enlighten.
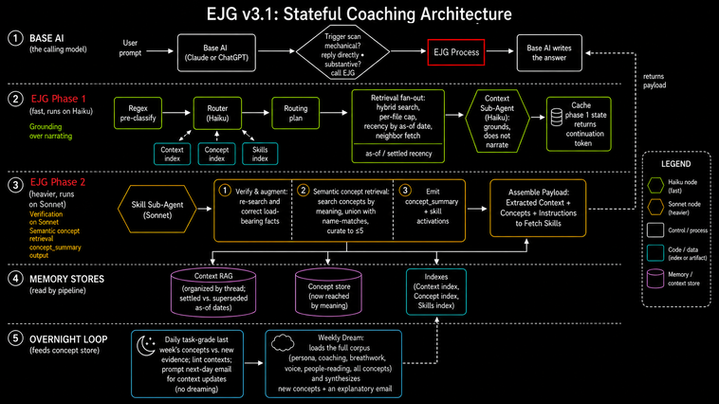
Eji (formerly “Closer Edge”) is what I call the personal AI system I’ve been building since early 2025, and what I’ve been writing about across this series as it’s evolved. My “context,” all the facts about my personal and professional life, lives in a set of files separated by category: work, family, health, and so on. A process I call “EJG” pulls together a deeper holistic and contextually aware reflection into my base AI model (Claude or ChatGPT mainly) to respond to every fresh prompt and again as needed through conversations.
I stay in the loop on all edits of that contextual memory, so they remain our shared source of truth. The pipeline’s only job is to fetch and package the right slices at the right moment. But what I realized is that even though I am in the loop on the content, I’m not in the structure or the retrieval of those files. And it was that packaging step where the trouble was brewing.

Where did the lie come from?
Three things all contributed to the issue, and I had to address them each at once.
The first was conflation. I had asked the packager for a cohesive narrative, so when it pulled two facts that were each true but unrelated, it smoothed them into one story and invented the seam that connected them. It was clear that the failure occurred at the point where it joined them, and it was clear that left to its own devices, AI will prioritize fluency over truth.
The second problem was staleness. The system tracked time, but it ranked “recent” by when a file was last edited rather than when the fact became true. A settled old fact that happened to get re-saved last week would outrank the one that was current, because the system confused freshly touched with freshly true.
The third was buried facts. The one record that would have killed the story sat too far away to match notes by meaning, so it never surfaced. The pipeline kept adding plausible matches and never went hunting for the fact that would have contradicted them.
Put together, I had a confident story built from real fragments, ranked by the wrong clock, missing the one fact that would have ended it.
How do you make a system know what’s true?
I changed four things to build a temporally smart truth-checking mechanism.
First, I told the packager to stop narrating and start reporting. Every claim now must ground in a specific retrieved fact, and two unrelated subjects or dates won’t get merged into one. The dates carry through, and choppy-but-true beats smooth-but-wrong. Its job is to report what’s on file and let the facts connect themselves.
Second, I moved the fact-check onto the stronger model. The pipeline runs two, a fast and cheap one (Haiku) for the first pass and a slower, stronger one (Sonnet) for the real reasoning. Verification is the kind of judgment that deserves the better engine and running it on the fast one trying to have the system grade its own homework.
Third, and this is the structural heart of it, I changed how the memory is organized. Within each category my notes had been a flat pile, at best loosely organized. Instead, I gave the system a way to sort them by thread, the actual sub-topic (IE: kids’ school, or a specific deal) so the check can avoid conflating disparate threads within the same file.
Lastly, I also gave it a way to mark a fact as superseded when a newer one replaces it, so a status that flips from pending to done leaves the old version behind as history. Paired with ranking by when a fact is true, the system finally knows what is settled. It’s still time-aware, but recency bias doesn’t drown out long-standing facts.

How much manual effort did it take to re-write my memory?
Here’s the part that surprised me, none of this touched the memory files themselves.
Every fix lived in the layer around them, in the index files and in the code of the processor itself. The index files are where the threads are tagged, the timestamps are categorized, and where what’s settled gets marked.
The notes I’ve been maintaining didn’t need to be touched at all. The intelligence wraps around the memory instead of rewriting it, so the part I curate stayed as I trust it, and the system is now smart enough to tell me what’s current, what’s settled, and how it knows.

But what about the other memory?
I fixed the memory that holds facts, but as I wrote in my last update, Eji contains a second memory, and that one needed structural improvement as well.
This system studies itself, how we have been working together, and writes short notes on the patterns it sees: the moves that land, the habits I fall into under pressure, and so on. The facts are the memory we share, and these are the memory of the patterns it recognizes in me, the people in my life, and the way it’s coaching me to interact.
The trouble was that this second memory was being written every night but read almost never.
When I send a message, the pipeline finds the right facts by meaning. This is how it surfaces the context without me having to write it all over each prompt. But it was retrieving its pattern memory simply by matching file names against the index. If it didn’t recognize a title, the pattern never loaded.
The fix put the two memories on equal footing. Now the system searches the patterns by meaning, the same way it searches the facts. It hands the base model a short brief on each one, what the pattern is, and what to do about it.

What does an AI Coach dream about?
There was still one more structural change needed to this version of the memory, though.
When I first set up the concept cycle, I had Eji “dream” every night. But I quickly realized that weeks would go by without it doing anything. I thought about making it more aggressive, even giving it a quota, but where I landed on its surface looks like I had it doing less. I ended up having it run less frequently but dig much deeper.
It used to sample a few relevant lenses when it dreamed. Now it loads everything that makes Eji what it is, the full corpus of skills and reference files. It can then go deep across all of it at once, from coaching philosophy and negotiation tactics to the way I read other people, my own voice and tells, and every pattern it’s already written That cross-domain reach is now how the system decides what to promote.
Doing that much every day doesn’t make sense, but dreaming just once a week would certainly drop details. As such, I’ve kept my daily “Eji memory” files to write about its own observations. But it doesn’t reflect anymore. Instead, it takes the day’s evidence and scores how the last set of patterns is holding up. The weekly one takes that scorecard and does the deep thinking, hypothesizing about new concepts that the future daily task will measure against. The fast loop grades, and the slow loop dreams.

Where else can does the shape around the model matter?
Structure shows up in the small stuff too. Eji has had an email channel for a while that I barely used, where anything I forward with a special tag in the subject line gets pulled in overnight. Then a real use came along.
My wife runs an AI system we set up together that tracks our kids’ activities. It sends out a weekly recap that keeps us on the same page, and that recap now flows into my briefing through that channel, with no manual effort. Now my wife’s AI and mine are linked in a way that makes our parenting more cohesive.
The whole thing has grown to around eighty memory and reference files, five skills, about a dozen python and typescript jobs, and a handful of standing jobs that keep it current. I’ve mirrored them all now on my PC as well, so it can be reproduced from scratch should I ever need to.

Where does this leave Eji?
Every fix here was the same move at a different layer. The memory itself didn’t change, but the shape of it changed completely.
Get the shape right and the same store does two jobs at once. It keeps the AI honest about what’s true today, and it gets sharper about the patterns I might otherwise miss.
For the past month I’ve been enjoying working with a system that can remember. Now I have a system that can make sense of what it remembers, and of me.

This is the 6th in a series about Eji, my personal AI negotiation and communications tool
-
The Eji System → komcp.com/shared-mastery-022826
-
Amplify Your Edge → komcp.com/amplify-your-edge-032326
-
Owning the Memory → komcp.com/own-the-memory-own-the-era-041326
-
More Reliable AI → komcp.com/reliable-ai-042726
-
Two Memories→ komcp.com/two-memories-050826
-
Structure of Memory→ komcp.com/structure-of-memory-062326
If you want to try the universal Eji package or compare notes on what you’ve been building, reach out. jkoenig@komcp.com
This article was also posted separately on LinkedIn:
https://www.linkedin.com/posts/jacobkoenig_last-week-my-ai-told-me-a-big-fat-lie-but-ugcPost-7475174071127810049-FVOG